
type
status
date
slug
tags
summary
category
password
icon
本文将介绍用ChatOllama这个项目实现与本地大语言模型的对话并通过这个项目搭建本地知识库进行问答
项目地址:
chat-ollama
sugarforever • Updated Nov 17, 2024
现在有很多支持本地运行大预言模型的项目和使用知识库的项目或者平台,之所以想介绍ChatOllama是因为个人使用过后感觉比其他项目好用。特别是它的本地知识库,也就是RAG问答效果,是我到现在用过的几个知识库中能检索到信息最准确的
虽然有不少平台支持知识库功能,但是实际使用的时候会发现检索回来的信息往往并不包含我们在知识库中提问的内容,RAG效果微乎其微
我看了一下发现字节的Coze平台算是比较好的,毕竟是大厂,我在Coze上做的知识库问答基本上都能检索到相关度较高的内容
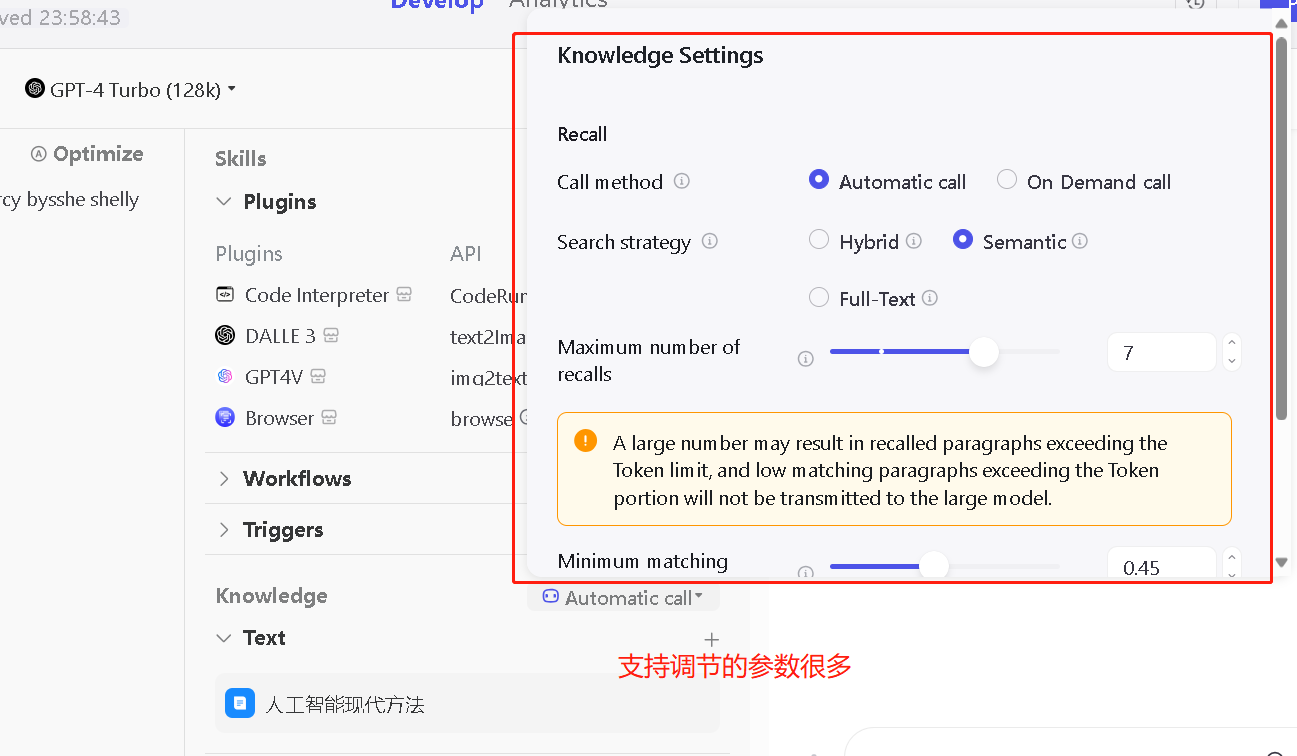
而且Coze支持调节的知识库参数很多,另外加上免费的GPT4-Turbo模型可以使用,说实话这个纯免费的知识库直接秒杀绝大部分付费知识库服务了已经。所以不想走弯路的小伙伴建议直接上手Coze平台的知识库功能
尽管Coze平台的知识库功能已经很强大了,但是一方面数据隐私性不高,毕竟是在人家的平台进行使用;另一方面Coze的知识库检索效果也还没有达到最好的效果
这里先简单介绍一下知识库服务利用的RAG技术,就是把文档分割成一个个片段并转换成向量存储在向量数据库中,然后用用户的询问去向量数据库中寻找与之距离最近的向量所代表的片段,即相关性最高的片段返回给模型,与用户的询问一起组成此次对话的prompt发给模型进行提问。这个看起来简单,但受到检索算法和向量模型等诸多因素的影响,实际去用几家知识库服务就会发现很多情况下检索回来的信息相关性都不是太高或者相关性高的片段很短
到现在我发现的就是Coze和ChatOllama的知识库效果比较好,Coze在可供选择的调节参数数量上胜出,而ChatOllama检索准确性上略胜一筹
另外从上面的介绍中,可以看出RAG技术搜索知识库里和用户提问相关的片段返回给大模型的这个过程,本质上只不过是把我们从源文本复制粘贴上下文的这个动作省略了,变成自动化的操作,其实我一开始知道这个技术还以为是模型在真的理解我提供的全部文本的基础上去回答我的问题哈哈哈
这辅助的一步虽然简单,当我们提供的文本超大时,就会量变引起质变。比如我给它一本厚的科普类的书,每当我有哪个部分看不懂,利用RAG技术去提问大模型,RAG会检索到书中那一部分的内容回答我的问题
如果只是几个问题,我们可以去自己复制整个段落、甚至整个部分的内容给大模型进行提问,但是如果有几十上百发个问题,反复进行这个过程就会很累。这时候利用RAG技术能帮我们节省不少时间,后面会举一个这个例子。这也只是RAG的应用场景之一,实际上RAG也可以利用到其他场景,比如在代码补全任务中检索知识库中的代码以及其他上下文给开发者生成建议代码。只不过大多数人用不到,可以了解一下
除了知识库技术,支持本地大语言模型对话是ChatOllama的主要功能。随着大模型的发展,未来部署在PC、移动端的本地大模型将会越来越多,可谓大势所趋
运行量化后的本地大模型如llama3, phi-3等并不用很好的配置,8G显存的Nvida显卡就能跑的比较流畅了,12G、16G以及更高显存的显卡直接起飞
所以总的来说,ChatOllama这个项目还是很不错的,感兴趣的小伙伴可以跟着教程部署一下。过程很简单,除了下载软件的时间,实际上几分钟就能部署完,几乎是一键部署
话不多说,开始部署!(全程请开魔法)
一、安装docker
此项目通过docker容器运行,如果没有安装docker,需要先去安装

安装很简单,跟着提示走就可以,安装完打开docker,并保持窗口打开时进行下一步
二、安装Ollama
Ollama是通过命令行与大模型进行交互的平台,ChatOllama项目就是与通过通过Ollama下载的模型进行对话的WebUI项目,所以需要先下载Ollama
来到ollama下载页,下载对应版本

这里有个小技巧,因为ollama下载模型都是直接安装在C盘的,下载过程中也没有提供变换路径的选项,但是我们可以通过如下的步骤变换ollama的默认模型下载路径
先在C盘以外的其他盘新建一个文件夹,文件夹名称随意
来到设置,搜索“高级系统设置”,点击“环境变量”
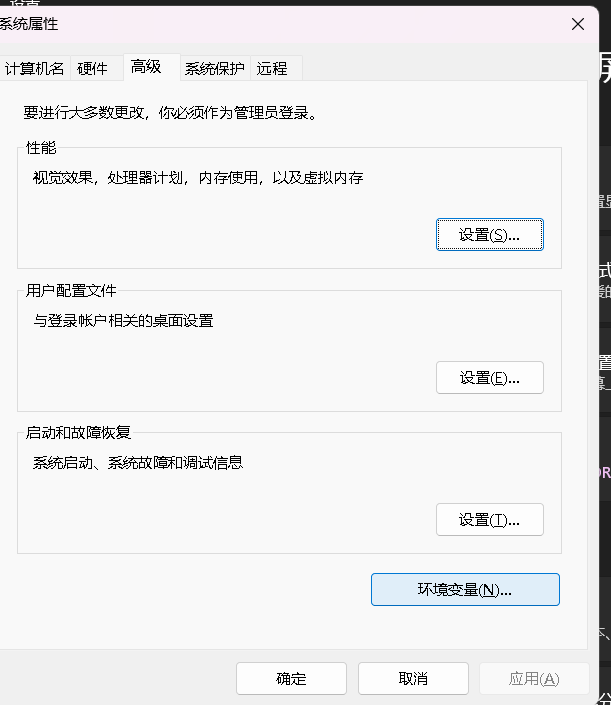
在系统变量中点击“新建”
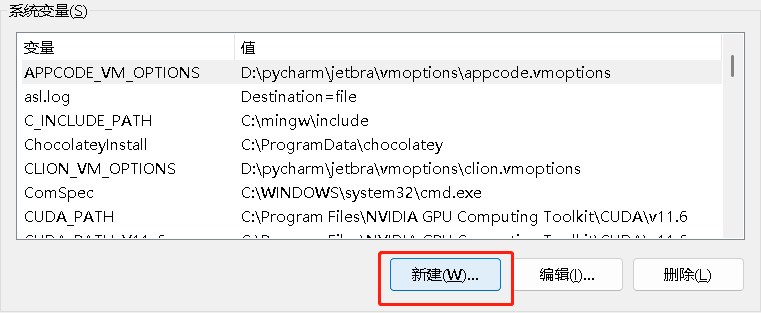
在变量名一栏输入“OLLAMA_MODELS”,这个不能变,然后变量值输入刚才创建的文件夹的路径,比如:
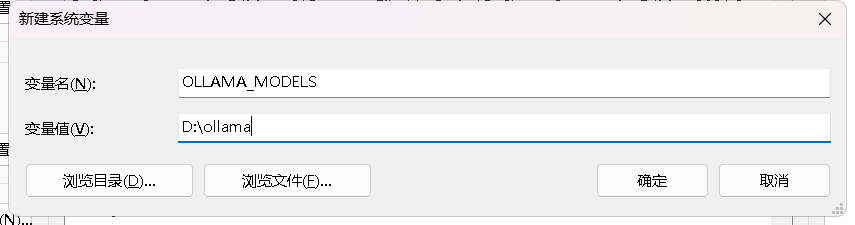
一路确定进行保存就设置好了
三、部署ChatOllama
接下来部署ChatOllama非常简单,不需要git拉取,不需要手动下载安装包,只需要把下面的代码保存为本地名为“docker-compose.yaml”的文件,然后通过一行代码启动就可以了
再在与文件相同的目录下运行这行代码(确保docker正在运行):
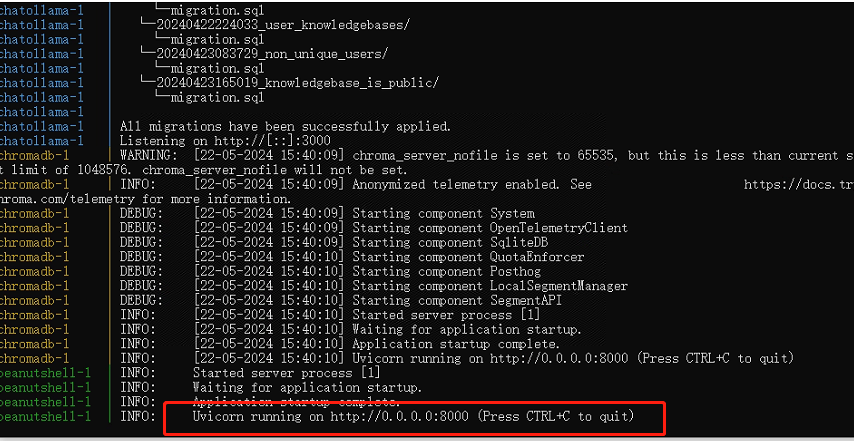
运行代码以后程序会开始拉取ChatOllama,出现最后这行提示就代表拉取完成
这时候注意这个cmd窗口不能关闭,如果你嫌cmd窗口碍眼,可以通过以下命令启动ChatOllama
这时候当程序启动完成,关闭cmd窗口程序仍能运行,但仍要保持docker开启
来到浏览器,在浏览器地址栏输入:localhost:3000 进入3000端口就能看到ChatOllama主页面了
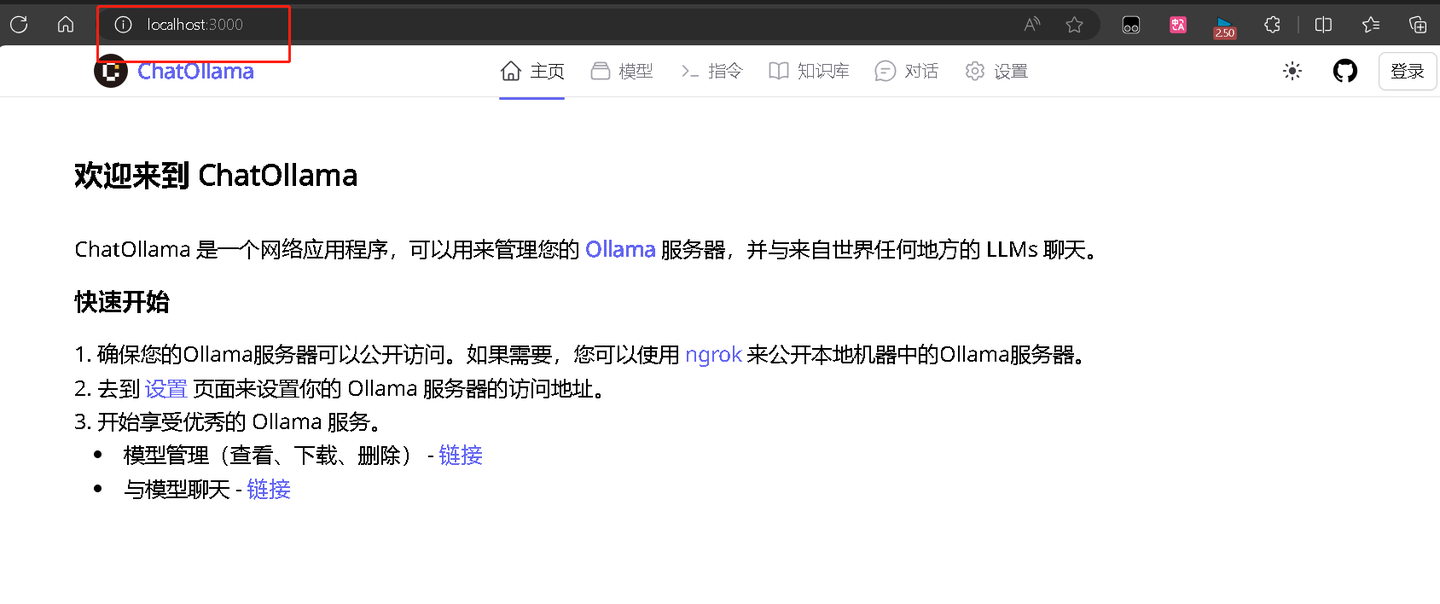
至此,ChatOllama就安装完成了,是不是超级简单!
四、配置模型
安装好ChatOllama后开始配置各个模型,ChatOllama支持的模型很多,其中包括所有可以从Ollama下载的模型,可以从Ollama library查看可下载的模型,以及google gemini,gpt系列模型,Claude系列,月之暗面moonshot,和Groq模型
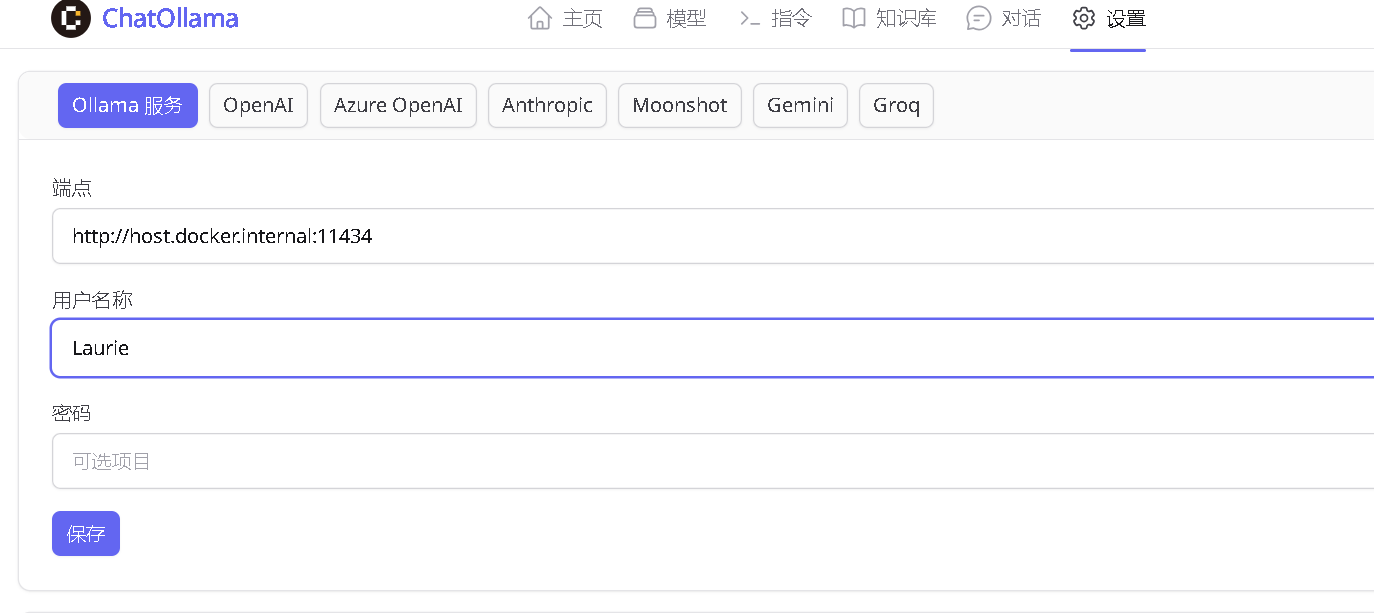
先配置Ollama上的模型,来到设置,将端口改为如下端口
用户名称和密码可以不填,点击保存
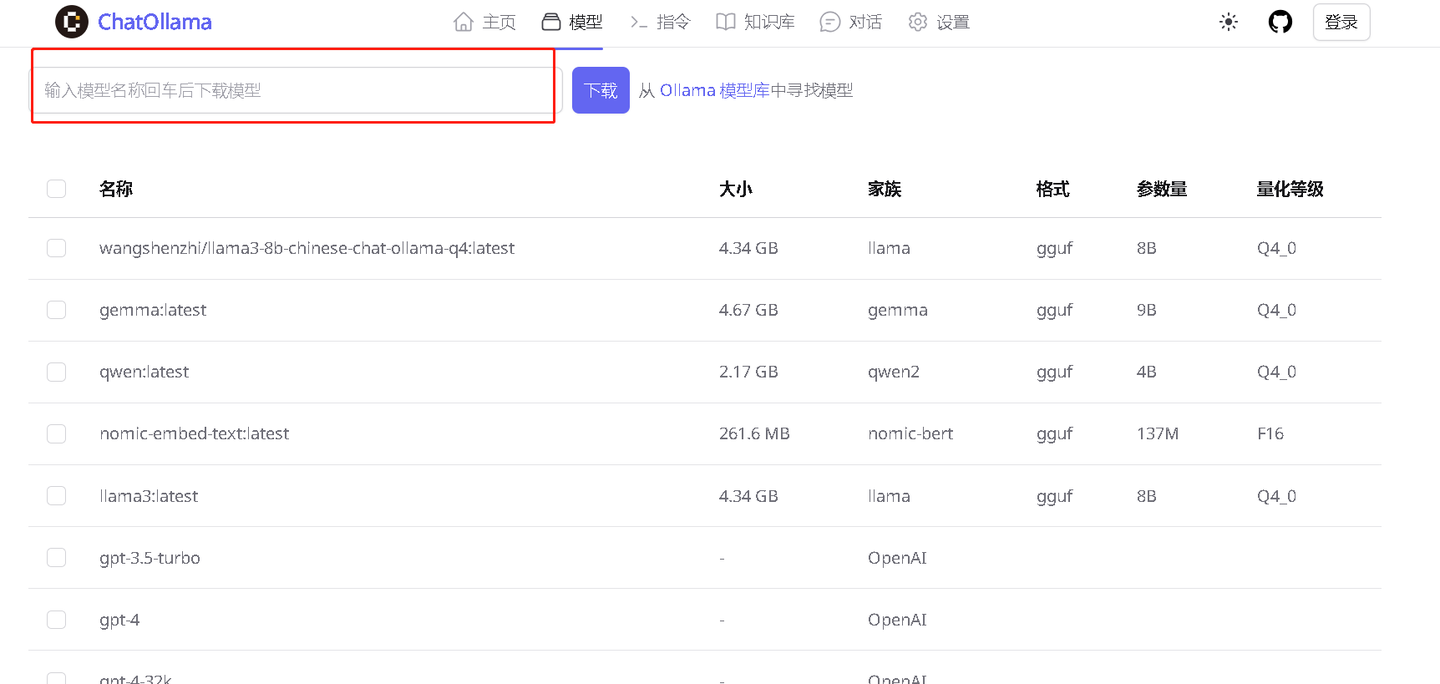
再到模型页面在搜索栏搜索Ollama library中需要下载的模型的模型名称,点击“下载”程序就会开始下载ollama模型(要保证ollama也在后台运行)
其他模型都是填入各家的API Key就可以使用了,另外这里ChatGPT建议使用oneapi的API Key,oneapi 地址:

原因是使用oneapi api key可以高并发,不仅平常对话不用担心每分钟的对话次数限制,使用向量模型生成知识库的时候也不会有限制,可以大大减少一些麻烦。并且openai前段时间开始不再给新用户赠送免费的五刀API Key,导致使用中转API key几乎成为大多数人唯一的使用openai api key的方式
当api key配置好后就可以开始对话了,上面的选项中有一个“指令”,实际上就是常见的system prompt设置选项,如果不懂可以尝试着用一下或者百度、问GPT就懂了
添加好ollama模型,在模型列表中选择相应模型就可以在本地和这些大模型对话了!其他通过API key运行,需要联网的大模型也是
五、知识库介绍及实例演示
来到知识库页面,点击创建就能创建新的知识库
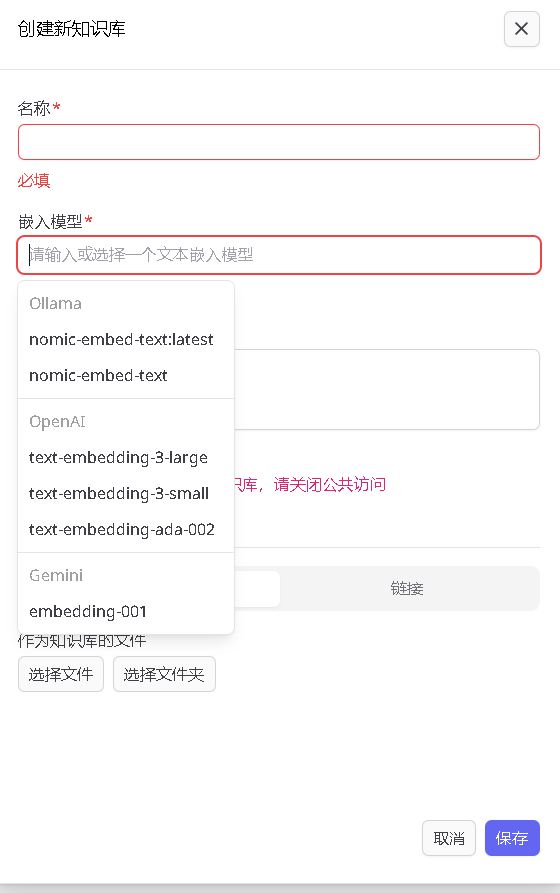
在跳出的窗口中,输入你想要的知识库的名称,然后选择向量模型。这里的向量模型有ollama,openai和gemini提供的三种向量模型可供选择,并且只有你在设置中配置了各自的api key,从ollama library库中下载了nomic-embed-text模型之后才会出现
不同的向量模型在不同的应用场景下各有优劣,但是我发现openai的text-embedding-3-large这个模型在我的大多数应用场景下表现效果都是最好的,应该大多数人都和我一样。然后建议使用oneapi 的api key,这样并发高,即使放很大的文件进去花费生成十几分钟生成知识库也不会超过使用限制
接下来描述可以不填,在下面选择文件就可以开始建立知识库了
举个例子,我通过text-embedding-3-large模型为《人工智能:现代方法 第四版》上册这本书生成了知识库,这本书比较厚,大概有3cm,整个过程耗时接近十分钟。这么大的文件Coze这种平台就会有限制,需要先将pdf文件进行分段,压缩大小再分成几个部分做知识库。这个过程中我发现了一个很好的处理pdf的网站,分享给大家


提取码: cjs4
生成好之后点击知识库名称就能开始对话
也可以从对话窗口选择知识库
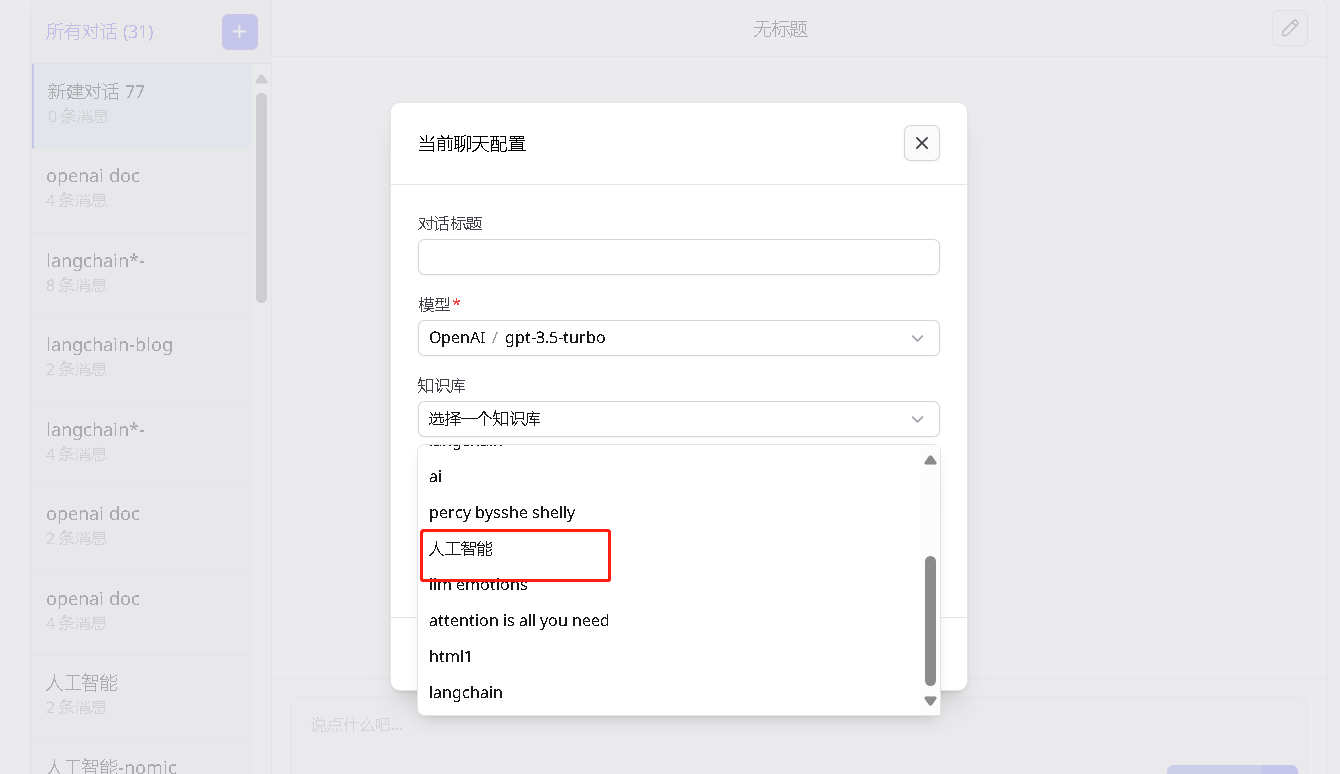
这里我用“介绍一下在线局部搜索”这个问题测试一下,看它能不能精确检索到相关信息
来到它检索返回的相关文本片段,在线局部搜索在书中是在4.5.3部分,我看了一下,它第一个检索回来的片段是4.5和4.5.1部分,第二个相关片段是4.5.2部分,第三个相关片段是4.5.3部分,接下来的几个片段基本上又往回去了,都是4.1不部分左右的内容
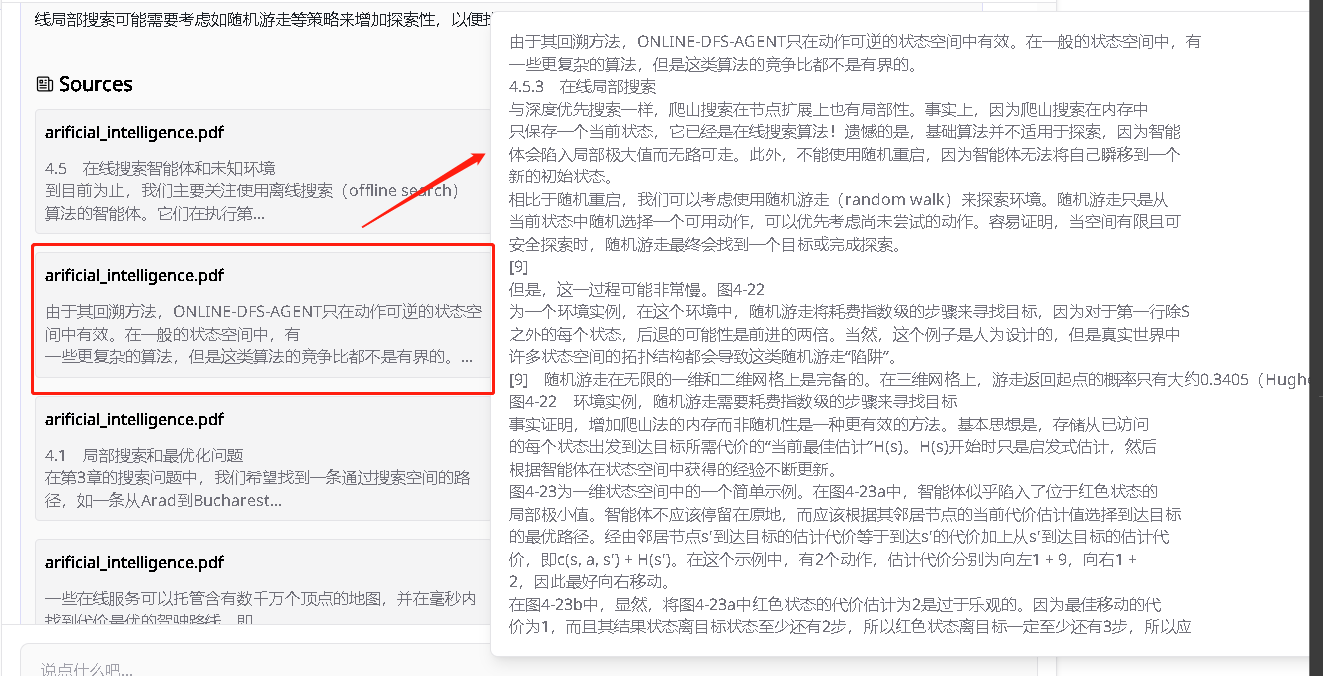
这个怎么说呢,第一部分我觉得是4.5.3才对,如果按相关性排序的话,但是这样按照逻辑将4.5部分的内容逐一喂给GPT感觉又好像挺合理的。不管怎么说,这次的RAG完美命中了相关的上下文片段,是非常不错的,因为我尝试过用其他平台进行同样的任务,要么干脆搜到的完全不相关,要么相关的部分少
这种应用场景还是很不错的,特别是针对这类科技类的,知识分散型的书,或者教科书,知识库返回的相关片段能包含较多相关知识的时候,回复质量和问答体验都会上升。但是如果是小说这就不行了,你不能问它小说中的某个人物怎么怎么样,因为小说人物的描写散落在全书各处,让它回答相关问题是不合适的。然而,如果模型训练的过程中训练了这本书的知识,那么再加上知识库,就可能达到1+1大于二的效果,所以没有明却的哪个应用场景适合什么的说法,大多数我感觉还是要具体问题具体分析
大家也可以像我这样通过RAG技术利用ChatOllama去学习一些知识分散型的书,理科同学可能用到的会比较多。文科同学可以尝试上面说的1+1大于二的应用场景
除了通过文件创建知识库,ChatOllama还支持通过网页链接创建知识库
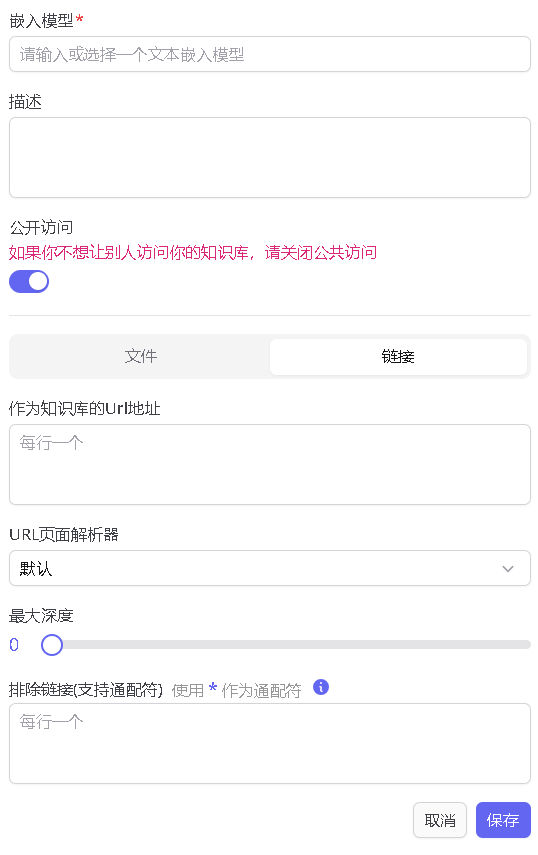
最大深度是爬取链接的层数,让GPT给我们解释一下
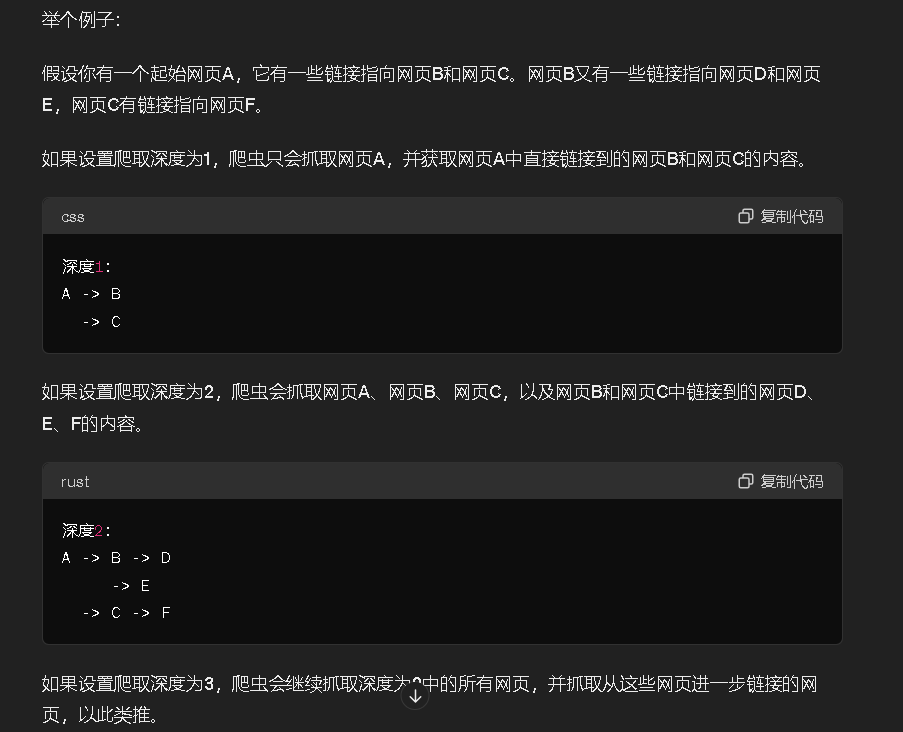
这里最大深度最好不要直接选三,因为我试了一下如果选三的话要很长时间生成知识库,昨天选三生成半个小时还没生成完,最后的效果也不是很理想
我一开始看到这个功能以为它可以从根链接爬取网站上所有其他页面的内容然后做成知识库来着,那这样的话一些平台的cookbook和doc就很容易看了,直接把根链接放到这里做成知识库,像问教科书上的问题那样问大模型的话就很方便了
另外也可以有很多其他应用场景。比如我之前就想做沃尔玛卖家知识库的知识库,需要爬取沃尔玛卖家知识库网站的所有页面然后再分别提取网页内容,因为沃尔玛卖家知识库页面是动态加载的,那个时候还费了点劲才弄好,如果这个项目能放个链接丢进去自动爬取其他所有子页面的内容做成知识库就好了
可惜拿openai和langchain的doc网站试了一下,发现它有时候可以爬取网站其他链接页面的内容,但大多数时候还是只能爬取输入的链接页面的内容,那就还是要一个个输入网站链接爬取内容后生成知识库。如果只是这样根据网页链接爬取内容的话其他很多项目也可以,不过作者说一直在优化,期待它变得更好吧
可惜拿openai和langchain的doc网站试了一下,发现它有时候可以爬取网站其他链接页面的内容,但大多数时候还是只能爬取输入的链接页面的内容,那就还是要一个个输入网站链接生成知识库。这个其他项目也可以,不过作者说一直在优化,期待它变得更好吧
小结
好了,今天分享了ChatOllama的安装以及用一个实例演示了知识库的作用,大家也可以像文章中一样运用ChatOllama的知识库去帮助自己学习知识分散型的书、教科书、项目文档网站等。如果有什么问题可以评论区留言或者私信我喔,然后文章诶过对你有用,希望可以给个三连~
- 作者:文雅的疯狂
- 链接:https://aiexplorer.rest//ai-powered-local-knowledge-base
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。