
type
status
date
slug
tags
summary
category
password
icon
字幕是给视频带来流量的重要因素之一,我自己就深有体会。有很多情况我刷视频不想外放,也没有随身戴耳机的习惯。如果刷到一个感兴趣的视频,但发现这个视频没字幕,而情况又不是很方便,那基本这个视频就会被我pass。除非实在感兴趣,我会收藏了后面再看
最近准备重新开始做视频,剪影一开始是我的首选。经常做视频的小伙伴都知道,剪影的字幕识别不仅准确率高,识别速度还快,吊打一众STT工具
之前是免费的,但最近剪影的字幕识别功能现在已经纳入到会员计划中,免费用户每个月有五次的试用机会

试了一下发现只有识别字幕后导出才算消耗一次次数,那这个其实还挺良心的,正常用户一个月应该做不到五个视频
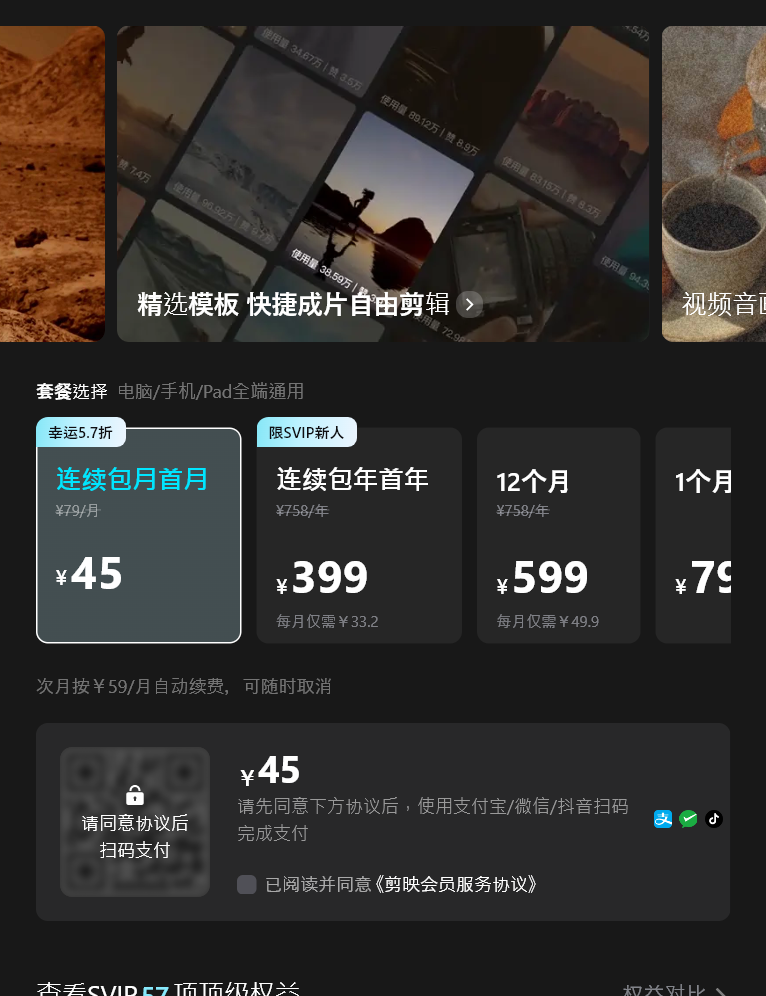
但连续包月也要45的月费对于做视频没那么频繁的我来说还是太贵了
为了防患于未然,以备不时之需,我在网上找了一些解决方案。最终确定下OpenAI开源的语音转文字模型(英文缩写STT, Speech to Text)Whisper作为终极方案
根据网上的测评,whisper模型的识别准确率和剪影不相上下
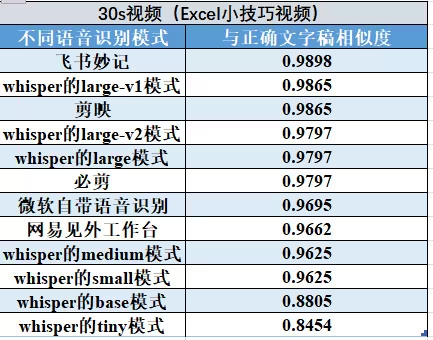
而且在这些工具中,现在唯有Whisper是免费,能直接拿来输出字幕文件的
Whisper的GitHub项目主页:
使用Whisper对电脑配置有一定要求,显存需要4~10G

如果显存不够,可以使用Whisper.cpp这个项目:
Whisper.cpp 项目通过将 Whisper 模型从Python迁移到 C++,允许用户在多种平台上(如 Windows、Linux 和 macOS)运行Whisper模型,同时显著降低对显存的要求。如最大的3GB Whisper-large模型使用whisper.cpp需要5GB左右(随着更新会慢慢变高),而使用pytorch版本(pt后缀的模型文件)需要10GB左右
我的电脑只有8GB显存,所以也选择了Whisper.cpp这个项目
GitHub上有一个叫WhisperDesktop的项目,是一个针对Whisper.cpp做的GUI程序,方便用户使用:
但是我发现这个项目问题很多,比如会无限复读:
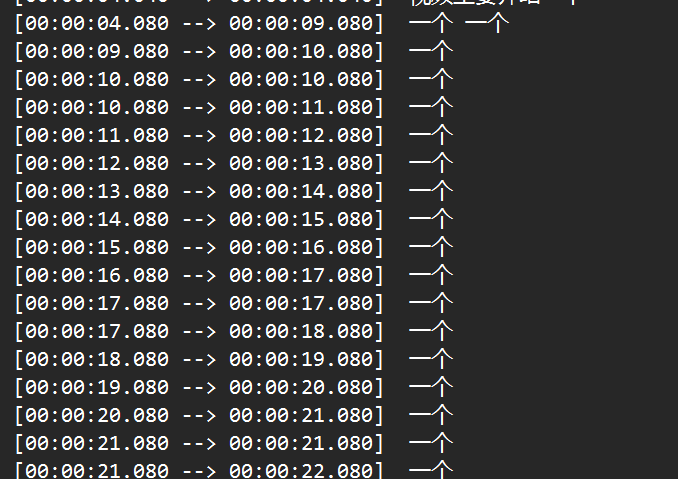
网友还反馈了其他问题,你可以在这篇帖子的评论区看看:
这个项目也是一年多没更新了
看到有其他人的修改版,我没试,不知道能不能work,感兴趣可以看一下:
两种使用Whisper.cpp进行语音转文字的方法
下面介绍两种能成功使用Whisper.cpp进行语音转文字的方法,在开始之前,确保你的电脑上安装了必要的工具和环境:
- Git
- FFmpeg(你也可以跟着官方教程走,用Make,但具体步骤要自己摸索哦)
1. 通过命令行使用Whisper.cpp进行转录
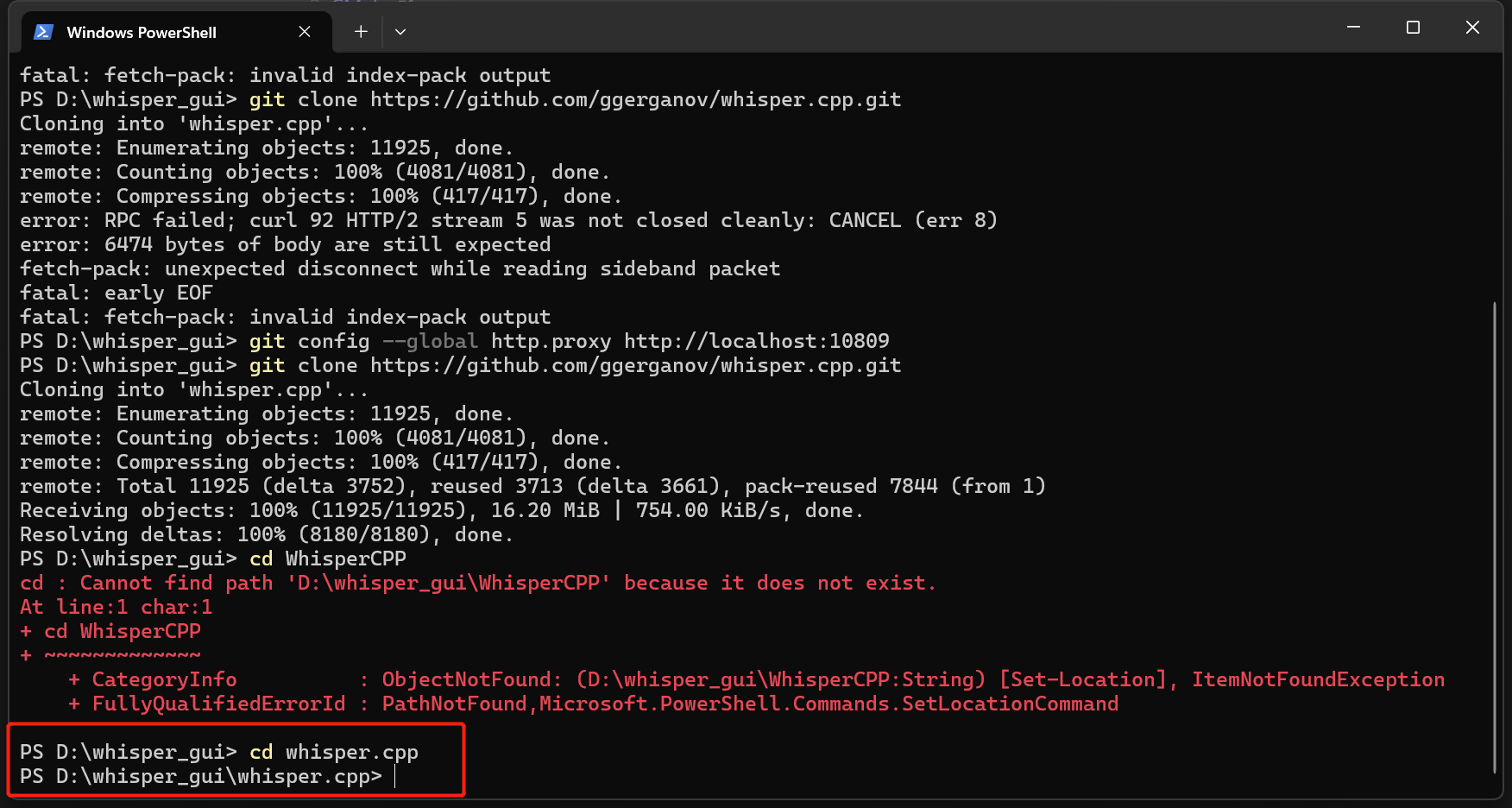
- 首先,确保你已经安装了上面所说的工具,在终端执行下面的命令先克隆whisper.cpp的GitHub仓库并进入Whisper.cpp文件夹
小提示:如果你的网不好,在克隆的时候老是克隆到一半失败,可以尝试为GIt在终端配置代理,输入下面的命令:
记得把“<你的代理端口>"更换成你实际的端口哦,在系统设置的代理设置里面查看具体端口
2. 下面开始编译Whisper.cpp,为了保持项目目录整洁,创建一个单独的
目录:
- 在build目录中运行以下命令以配置项目:
- 接着运行以下命令编译项目:
这里我碰到了因为中文GBK编码导致的编译错误
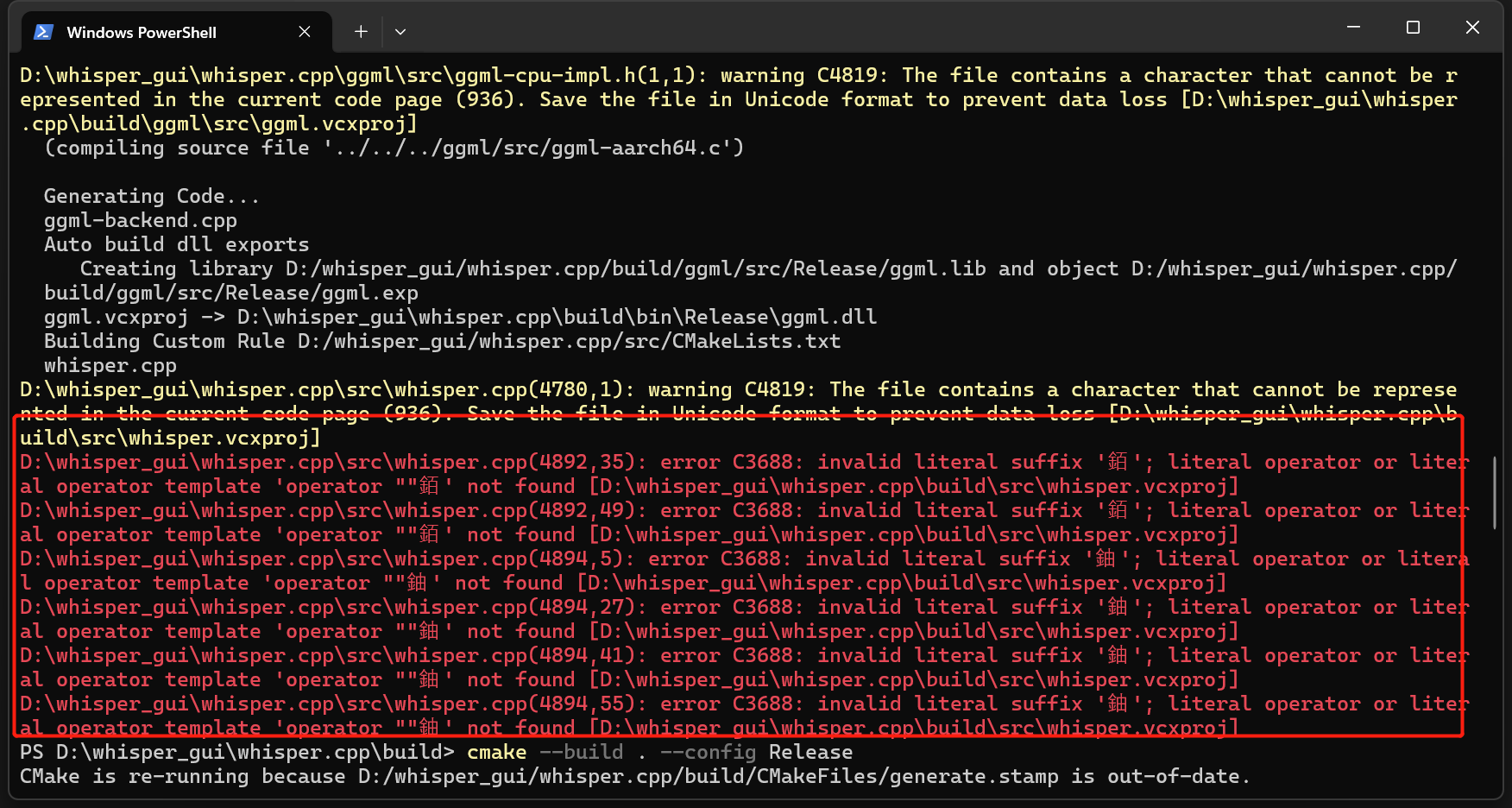
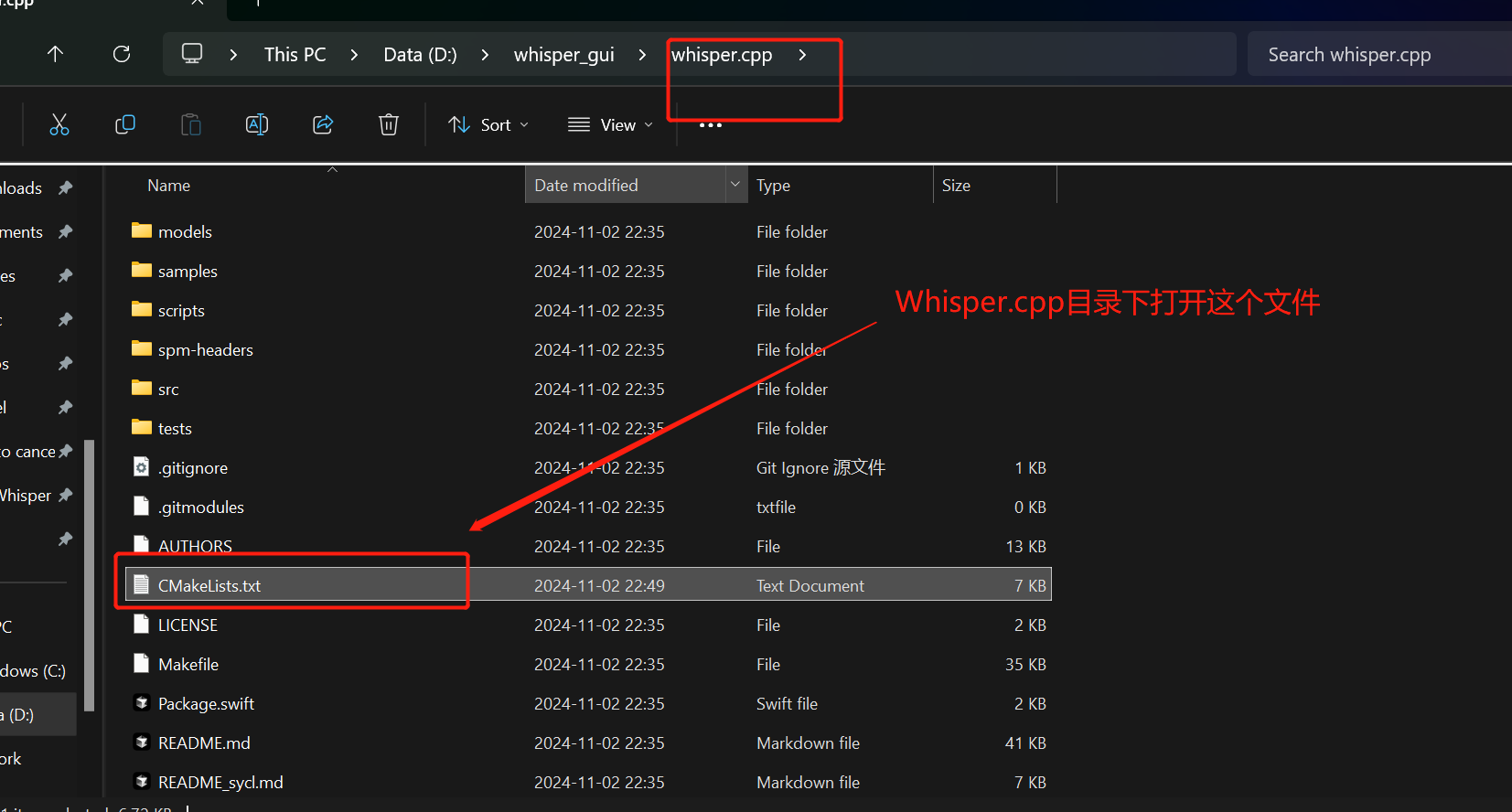
不用担心,先回到Whisper.cpp根目录,打开CMake6. 配置文件CMakelists.txt文件
然后在顶部加入下面这行代码,强制编译器使用UTF-8编码:
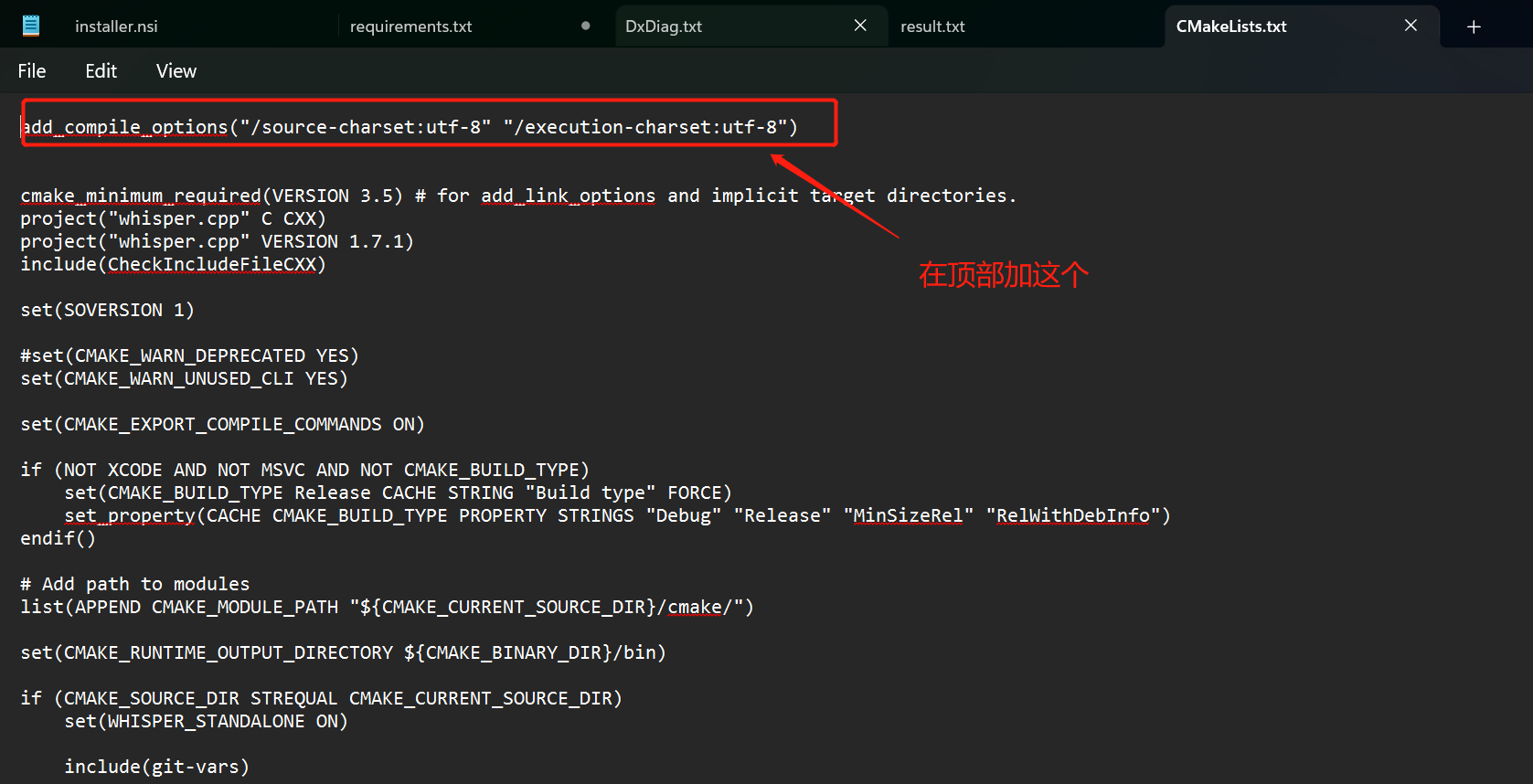
这样就能正常编译不报错了
5. 刚才编译成功后会在build目录下生成可执行文件"main.exe",位于build/bin/Release目录下
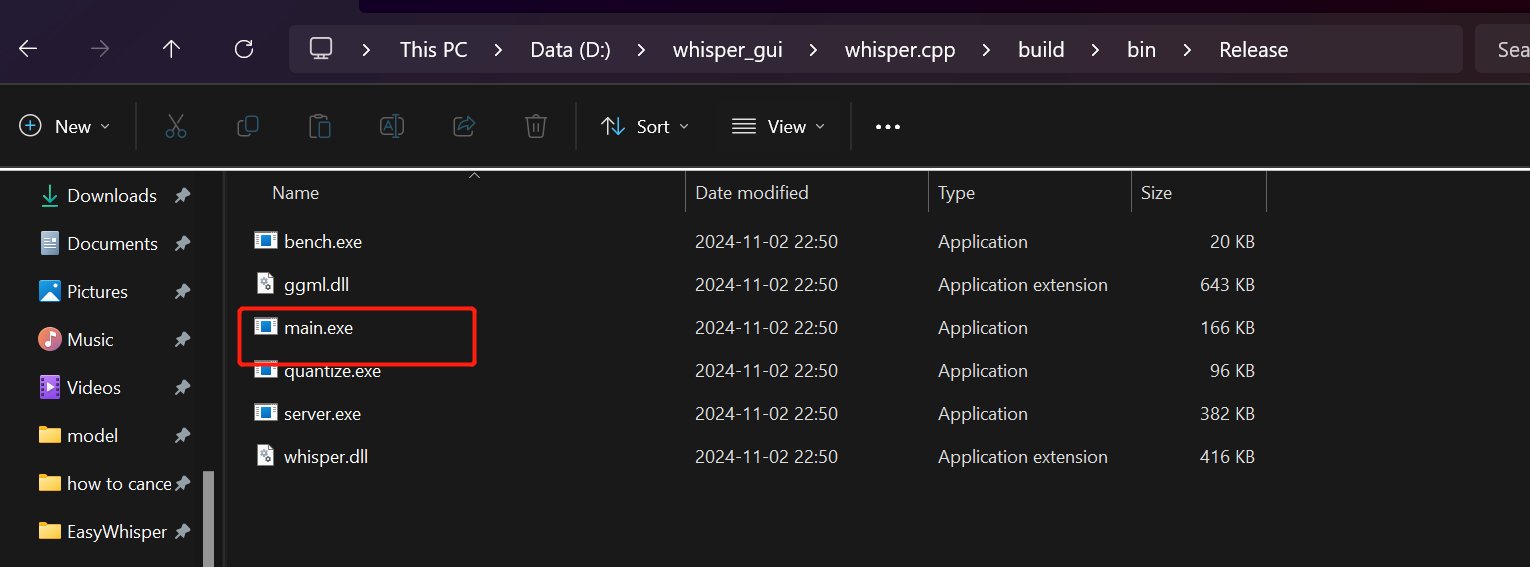
6. 我们就是使用“main.exe"这个可执行文件用Whisper.cpp在终端进行语音转文字的。但是在转换之前,还必须保证转换的音频文件是16000HZ的单声道wav文件,我们用FFmpeg来处理音频文件
在你音频所在的目录,打开终端,执行以下命令:
记得用文件名替换上面命令中的对应位置,命令解释:
i 你的音频.mp3:指定输入音频文件,可以是任意支持的格式(如 MP3、M4A、AAC 等)
ar 16000:设置输出音频的采样率为 16kHz(16000 Hz)。
ac 1:设置输出音频的通道数为 1(单声道),通常语音识别需要单声道音频。
output_audio.wav:指定输出文件的名称和格式,这里输出为 WAV 格式
- 音频准备好了,模型也需要下载,你可以去这里下载别人已经转换好的ggml格式Whisper模型:
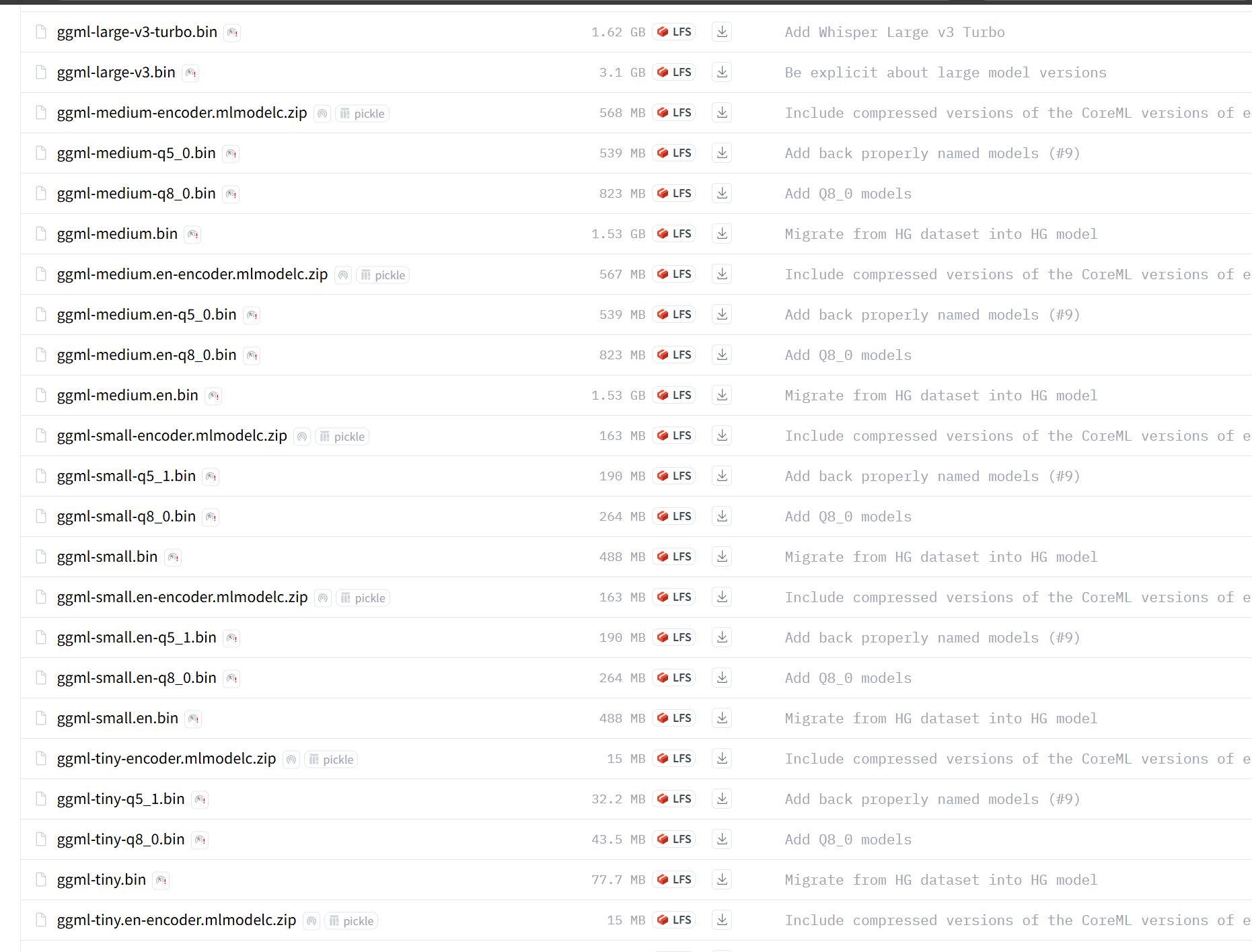
Whisper模型性能从低到高分别为tiny, base, small, medium, turbo, large. 这上面还有好多“q5_0", "q8_0"结尾的,这些是量化模型,就是阉割版,量化精度越高性能越好。然后还有一些以”en"结尾的模型是只支持英文转录,没有这个的模型的都是支持多语言转录
不要用终端下载哦,速度非常慢,而且我感觉实际上也下不了,我的经常下一会儿就自己退出了
你可以在这里下载模型,每个版本我分别下了一个最强模型在里面,另外下了一个5精度量化的large-v3模型:
- 好了!下面可以正式开始转录音频了,回到刚才main.exe文件所在的Release文件夹,打开终端,Win11右击选择”在终端打开“,Win10按住Shift,右击选择”在powershell中打开",之后输出下面的命令进行音频转换:
“-m"用来指定模型,”-f"用来指定音频,比如我的是这样:
执行这个命令音频就转换完成啦!
Whisper.cpp还支持通过"-l"参数设置语言,通过“-ml"参数控制生成每行生成的字幕的字数,通过”--print-colors"使得输出的字幕呈彩色,等等,完整的参数支持你可以在Whisper.cpp项目主页查看
最后在终端输出的字幕是这样的:

虽然不是直接的srt文件,你可以让ChatGPT写个脚本,把这样的输出转换成标准的srt格式就可以啦
2. 通过EasyWhisper使用Whisper.cpp进行转录
这是我用python写的一个使用Whisper.cpp进行语音转录的Tkinter GUI,项目地址:
GUI:
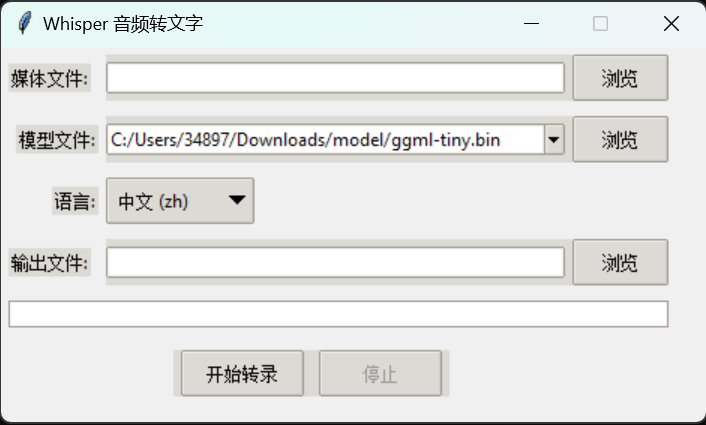
这个项目有如下特点:
- 可以直接选中视频文件进行转录,程序会自动使用ffmpeg提取视频音频并处理成16kHZ单声道wav音频并用Whisper.cpp模型转录。支持多种格式:
- 音频:WAV、MP3、M4A、FLAC
- 视频:MP4、AVI、MKV、MOV FFmpeg还可以支持更多的格式,如果现在没有你需要的格式可以自己在项目的src目录下的main.py文件中添加,我当时懒得加太多
- 支持输出为 SRT 字幕文件或纯文本
- 支持多种语言
- 支持实时显示转录进度 另外如果你想更精细地控制每行字幕的数量,可以在src目录下的main.py文件中的这里修改“-ml"参数后面的值实现: 由于项目是使用Python编写,你需要确保电脑上安装了Python,使用如下命令验证Python的安装:
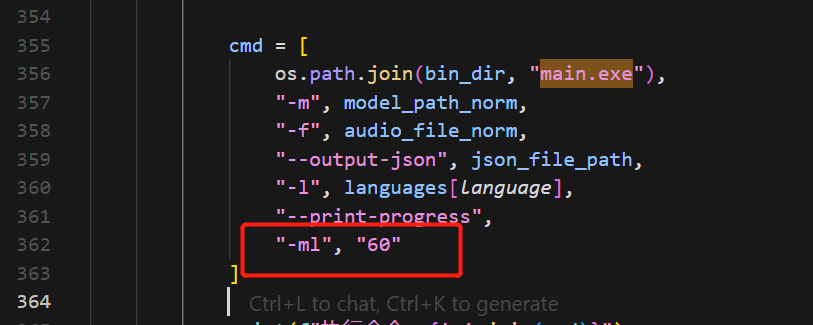
没有报错,输出版本就是成功安装且添加到环境变量了
接下来,克隆EasyWhisper到本地:
在EasyWhisper目录下安装依赖:
如果没有问题,双击Easywhisper目录下的“启动.bat"批处理文件就会打开上面的GUI,之后选择音频、模型文件、和输出路径就可以开始转换了
建议把模型单独放在一个文件夹存放,程序可以自动识别当前文件夹中所有的bin后缀的模型文件并放在下拉框里,这样就不用到处找模型文件了
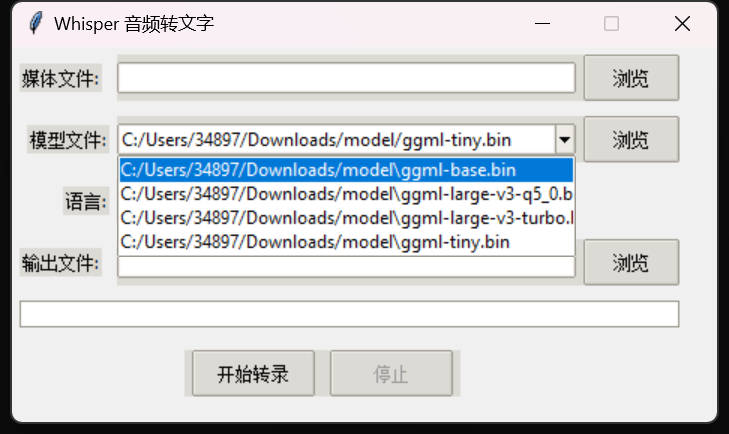
但是有个问题,大家使用的时候可能发现虽然能用,但比自己在终端转录慢,暂时不确定为什么会有这个问题
唯一的解决方法是自己用上面“通过命令行使用Whisper.cpp进行转录”部分提到的编译生成的可执行文件和两个依赖替代掉项目自带的文件,步骤如下:
再次来到我们从Whisper.cpp根目录下编译生成的Release文件夹中,选中“main.exe", "whisper.dll", "ggml.dll"这三个文件
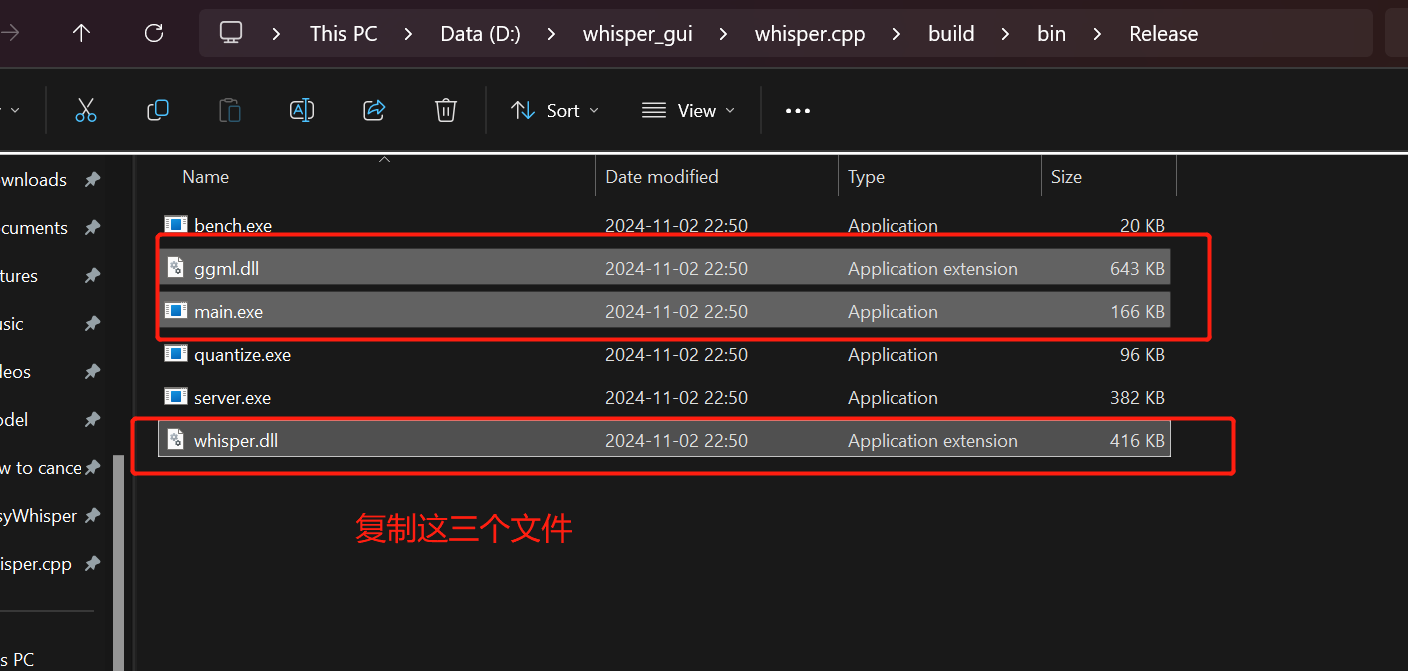
替换掉EasyWhisper目录下“bin"文件夹中的三个同名文件
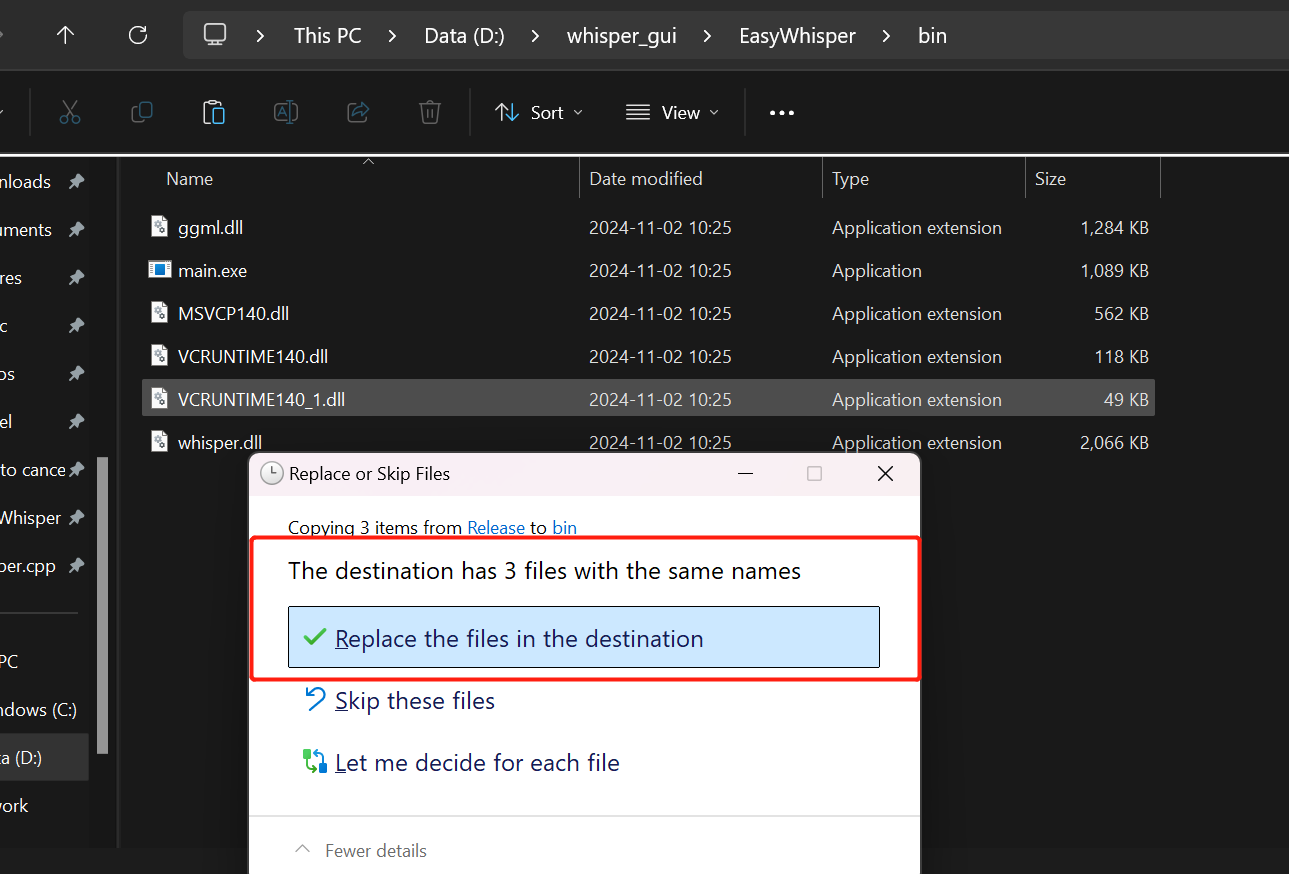
这时候再重新打开GUI进行转录就会快很多了,可能是跟每个机器的配置和环境有关吧
我使用另外两个电脑测试都是没有问题的,大家部署过程中有什么问题欢迎在下面评论或咨询我
- 作者:文雅的疯狂
- 链接:https://aiexplorer.rest//stt-tool
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。